[90]:
# Install tutorial-specific dependencies (e.g., matplotlib for plotting)
%pip install matplotlib seaborn kagglehub --quiet
Note: you may need to restart the kernel to use updated packages.
[1]:
import kagglehub
import numpy as np
import pandas as pd
import os
from pyhctsa.calculator import FeatureCalculator
from scipy.signal import filtfilt, butter
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from sklearn.svm import LinearSVC
from sklearn.metrics import confusion_matrix
import seaborn as sns
✨ Tutorial: Bonn EEG (end-to-end pyhctsa workflow)¶
This tutorial provides a hands-on walkthrough of the standard pyhctsa pipeline using data from the Bonn EEG dataset. We will move through the entire research cycle—starting with raw time-series data and ending with interpreted classification results.
What You Will Learn
The workflow is divided into four key phases:
Data Preparation: Structuring your time-series data and associated metadata into the required pyhctsa format.
Feature Extraction: Leveraging the massive feature library to compute thousands of properties for each time series.
Data Processing & Cleaning: Handling missing values, normalizing features, and preparing the resulting feature matrix for analysis.
Analysis & Visualization: Implementing classification algorithms to distinguish between data classes and using built-in visualization tools to interpret which features drive those differences.
⬇️ (1) Download the Bonn EEG Dataset¶
Download the Bonn EEG dataset directly from kaggle
EEG recordings from healthy individuals and patients with epilepsy
Five distinct classes: A, B, C, D and E
Each class has 100 single-channel EEG segments, with each segment comprising 23.6 seconds of EEG data, sampled at 173.61 Hz, yielding a length 4096 sample time series
A = Z, B = O, C = N, D = F, E = S
A/Z = eyes open healthy (eyesOpen)
B/O = eyes closed healthy (eyesClosed)
C/N = seizure free interval for epileptic patient (hippocampus)
D/F = seizure free interval epileptic patient, non-seizure epileptogenic zone (epileptogenic)
E/S = During seizure epileptic patient (seizure)
[2]:
path = kagglehub.dataset_download("quands/eeg-dataset") # download from kagglehub
print(os.listdir(os.path.join(path, 'Dataset'))) # display the subfolders
['N', 'Z', 'S', 'F', 'O']
Define the class mappings
[3]:
mappings = {'Z': 'eyesOpen', 'N': 'hippocampus', 'F': 'epileptogenic', 'S': 'seizure', 'O': 'eyesClosed'}
🗳 (2) Pre-process the EEG recordings¶
Pre-filter with a 40Hz low pass
[4]:
def unpack_subfolder(base_path : str, which_folder : str) -> pd.DataFrame:
cutoff_freq = 40.0 # 40 Hz
fs = 173.61 # sample rate in Hz
order = 4 # 4th order butterworth filter
nyq = 0.5 * fs
normal_cutoff = cutoff_freq/nyq
b, a = butter(order, normal_cutoff, btype='lowpass')
if which_folder.lower() in ['n', 'z', 's', 'f', 'o']:
label = mappings[which_folder.upper()]
path = os.path.join(base_path, 'Dataset', which_folder)
assert(os.path.exists(path))
# check number of files
subfiles = os.listdir(path)
num_subfiles = len(subfiles)
if num_subfiles != 100:
print(f'More files than expected. Expected 100, got {num_subfiles}')
all_series = []
for subfile in subfiles:
data = np.loadtxt(os.path.join(path, subfile))
filtered_data = filtfilt(b, a, data)
all_series.append(filtered_data)
df = pd.DataFrame(all_series)
df['label'] = label
else:
raise ValueError(f"Unknown folder: {which_folder}")
return df
Concatenate all time-series instances into a single dataframe
[5]:
df_series = pd.concat([unpack_subfolder(path, c) for c in ['N', 'Z', 'S', 'F', 'O']])
[6]:
df_series.head(3)
[6]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 4088 | 4089 | 4090 | 4091 | 4092 | 4093 | 4094 | 4095 | 4096 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -76.002880 | -8.160361 | 36.130147 | 37.625116 | 0.235783 | -41.989949 | -54.718865 | -38.386317 | -20.373990 | -17.291749 | ... | 180.432287 | 164.583116 | 150.705251 | 157.809372 | 194.080194 | 235.464085 | 228.103199 | 127.476462 | -51.043101 | hippocampus |
| 1 | 34.000406 | 31.416358 | 27.038342 | 21.346209 | 15.747189 | 10.304919 | 4.426019 | -1.259340 | -5.333748 | -7.425735 | ... | -22.703815 | -16.919187 | -13.739674 | -12.329390 | -8.005106 | 1.240274 | 7.273179 | -2.612481 | -28.999855 | hippocampus |
| 2 | -56.990550 | -71.547664 | -75.119898 | -67.728569 | -58.999405 | -56.182465 | -56.529083 | -53.060212 | -44.914053 | -38.376826 | ... | -70.041801 | -60.266899 | -43.302333 | -26.943180 | -24.632308 | -40.924329 | -56.324522 | -40.254580 | 10.991437 | hippocampus |
3 rows × 4098 columns
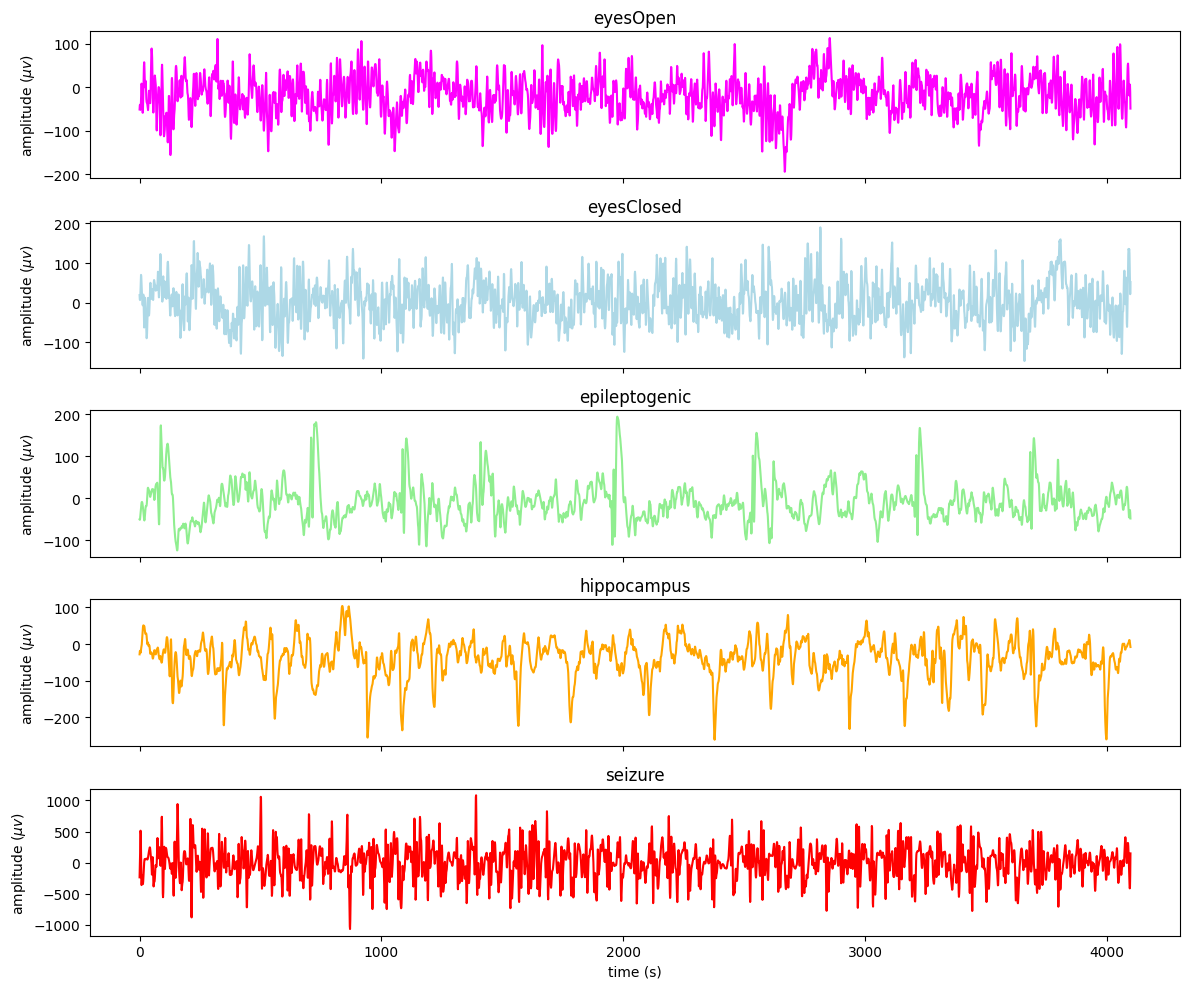
Plot first example from each class:
[7]:
fs = 173.61
fix = False
t = np.arange(df_series.drop(columns=['label']).shape[1])/fs
fig, ax = plt.subplots(5, 1, sharex=True, figsize=(12, 10))
df_series[df_series['label'] == 'eyesOpen'].drop(columns=['label']).iloc[0 if fix else np.random.randint(0, 99)].plot(x=t, ax=ax[0], title="eyesOpen", c='magenta')
df_series[df_series['label'] == 'eyesClosed'].drop(columns=['label']).iloc[0 if fix else np.random.randint(0, 99)].plot(x=t, ax=ax[1], title="eyesClosed", c='lightblue')
df_series[df_series['label'] == 'epileptogenic'].drop(columns=['label']).iloc[0 if fix else np.random.randint(0, 99)].plot(x=t, ax=ax[2], title="epileptogenic", c='lightgreen')
df_series[df_series['label'] == 'hippocampus'].drop(columns=['label']).iloc[0 if fix else np.random.randint(0, 99)].plot(x=t, ax=ax[3], title="hippocampus", c='orange')
df_series[df_series['label'] == 'seizure'].drop(columns=['label']).iloc[0 if fix else np.random.randint(0, 99)].plot(x=t, ax=ax[4], title="seizure", c='red')
plt.xlabel("time (s)")
ax[0].set_ylabel(rf"amplitude ($\mu v$)")
ax[1].set_ylabel(rf"amplitude ($\mu v$)")
ax[2].set_ylabel(rf"amplitude ($\mu v$)")
ax[3].set_ylabel(rf"amplitude ($\mu v$)")
ax[4].set_ylabel(rf"amplitude ($\mu v$)")
plt.tight_layout()
⚙️ (3) Instantiate a calculator in pyhctsa¶
While you can run the calculator with the full hctsa feature set, for the sake of brevity, we will use a custom yaml file with a selected subset of 110 “fast” feature functions:
[8]:
calc = FeatureCalculator(config_path="./custom.yaml")
Loaded 110 master operations.
[9]:
bonn_eeg = df_series
[10]:
data_df = bonn_eeg.drop(columns=['label']).to_numpy() # drop the labels column for computing features on the time-series data
To ensure everything is working as expected, we will first run the calculator on the first instance/time-series of the data frame
[11]:
res = calc.extract(data_df[0, :])
Evaluating 110 partialed functions. Strap in!...
Feature extraction completed in 0.120 seconds.
[12]:
res
[12]:
| hrv_classic.pnn5 | hrv_classic.pnn10 | hrv_classic.pnn20 | hrv_classic.pnn30 | hrv_classic.pnn40 | hrv_classic.lfhf | hrv_classic.vlf | hrv_classic.lf | hrv_classic.hf | hrv_classic.tri | ... | ac_nl_0_2_6 | ac_nl_0_3_6 | ac_nl_0_4_6 | ac_nl_0_5_6 | ac_nl_1_1_2 | ac_nl_1_1_3 | ac_nl_1_2_2 | ac_nl_1_3_3 | ac_nl_2_2_3 | ac_nl_2_3_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | |||||||||||||||||||||
| ts_1 | 0.988037 | 0.975098 | 0.943359 | 0.915039 | 0.887207 | 1.438589 | 16.373641 | 38.574764 | 26.814297 | 3.080451 | ... | 1.634811 | 1.597856 | 1.577479 | 1.561968 | 3.240279 | 2.838081 | 3.121141 | 2.618175 | 2.834442 | 2.684552 |
1 rows × 347 columns
Now that everything is working, let’s scale up to the full dataset:
[33]:
res = calc.extract(data_df)
Evaluating 110 partialed functions. Strap in!...
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:92: RuntimeWarning: divide by zero encountered in log
log_s = np.log(s)
/opt/anaconda3/envs/pyhctsa-latest/lib/python3.12/site-packages/numpy/_core/_methods.py:190: RuntimeWarning: invalid value encountered in subtract
x = asanyarray(arr - arrmean)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:221: RuntimeWarning: divide by zero encountered in log
h_shann = -s * np.log(s)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:221: RuntimeWarning: invalid value encountered in multiply
h_shann = -s * np.log(s)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:228: RuntimeWarning: divide by zero encountered in log
out['sfm'] = 10 * np.log10(np.exp(np.mean(np.log(s))) / np.mean(s))
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:228: RuntimeWarning: divide by zero encountered in log10
out['sfm'] = 10 * np.log10(np.exp(np.mean(np.log(s))) / np.mean(s))
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:242: RuntimeWarning: divide by zero encountered in log
out['logarea_2_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:253: RuntimeWarning: divide by zero encountered in log
out['logarea_3_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:266: RuntimeWarning: divide by zero encountered in log
out['logarea_4_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:281: RuntimeWarning: divide by zero encountered in log
out['logarea_5_1'] = np.sum(np.log(split[:, 0])) * dw
Feature extraction completed in 31.016 seconds.
[OPTIONAL] (3.5)¶
Time-series feature extraction is computationally intensive. To speed up processing, pyhctsa allows you to distribute the workload across multiple CPU cores on your local machine using the LocalDistributor:
[36]:
from pyhctsa.distribute import LocalDistributor
[ ]:
# create a LocalDistributor
dist = LocalDistributor(n_workers=6) # set to the number of physical cores available on your local machine...
[38]:
res = calc.extract(data_df, distributor=dist)
Evaluating 110 partialed functions. Strap in!...
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:92: RuntimeWarning: divide by zero encountered in log
log_s = np.log(s)
/opt/anaconda3/envs/pyhctsa-latest/lib/python3.12/site-packages/numpy/_core/_methods.py:190: RuntimeWarning: invalid value encountered in subtract
x = asanyarray(arr - arrmean)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:221: RuntimeWarning: divide by zero encountered in log
h_shann = -s * np.log(s)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:221: RuntimeWarning: invalid value encountered in multiply
h_shann = -s * np.log(s)
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:228: RuntimeWarning: divide by zero encountered in log
out['sfm'] = 10 * np.log10(np.exp(np.mean(np.log(s))) / np.mean(s))
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:228: RuntimeWarning: divide by zero encountered in log10
out['sfm'] = 10 * np.log10(np.exp(np.mean(np.log(s))) / np.mean(s))
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:242: RuntimeWarning: divide by zero encountered in log
out['logarea_2_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:253: RuntimeWarning: divide by zero encountered in log
out['logarea_3_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:266: RuntimeWarning: divide by zero encountered in log
out['logarea_4_1'] = np.sum(np.log(split[:, 0])) * dw
/Users/jmoo2880/Documents/pyhctsa-latest/pyhctsa/pyhctsa/operations/spectral.py:281: RuntimeWarning: divide by zero encountered in log
out['logarea_5_1'] = np.sum(np.log(split[:, 0])) * dw
Feature extraction completed in 6.369 seconds.
Here we can see that by utilising parallel computing, we can reduce our feature extraction time by a factor of ~4.
[OPTIONAL] Load results from the full feature set¶
If you wish to access the results from the full hctsa feature set, but do not want to run the full feature set locally due to time contraints, you can download and import the pre-computed results from https://doi.org/10.6084/m9.figshare.31290259
[8]:
LOAD_PRECALCULATED_RESULTS = True # set to true to load the results
if LOAD_PRECALCULATED_RESULTS:
res = pd.read_pickle("./bonn_eeg_results.pkl") # point to the path where the downloaded results exist
[9]:
res.head(5)
[9]:
| hrv_classic.pnn5 | hrv_classic.pnn10 | hrv_classic.pnn20 | hrv_classic.pnn30 | hrv_classic.pnn40 | hrv_classic.lfhf | hrv_classic.vlf | hrv_classic.lf | hrv_classic.hf | hrv_classic.tri | ... | surrogate_test_RP_99_o3.o3_zscore | surrogate_test_RP_99_o3.o3_f | surrogate_test_RP_99_o3.o3_mediqr | surrogate_test_RP_99_o3.o3_prank | surrogate_test_RP_99_tc3.tc3_p | surrogate_test_RP_99_tc3.tc3_zscore | surrogate_test_RP_99_tc3.tc3_f | surrogate_test_RP_99_tc3.tc3_mediqr | surrogate_test_RP_99_tc3.tc3_prank | multi_scale_entropy_1_10_2_0p15_rescale_tau.out | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | |||||||||||||||||||||
| ts_1 | 0.988037 | 0.975098 | 0.943359 | 0.915039 | 0.887207 | 1.438589 | 16.373641 | 38.574764 | 26.814297 | 3.080451 | ... | -2.217531 | 0.000000 | 1.393878 | 0.02 | 0.004159 | 2.865863 | 0.011524 | 2.146499 | 0.06 | NaN |
| ts_2 | 0.979736 | 0.959473 | 0.916504 | 0.875244 | 0.831299 | 1.910163 | 16.994118 | 50.579037 | 26.478908 | 2.559026 | ... | 0.237313 | 0.345205 | 0.250219 | 0.78 | 0.010484 | -2.559445 | 0.000000 | 1.908045 | 0.02 | NaN |
| ts_3 | 0.979492 | 0.960938 | 0.929443 | 0.891602 | 0.852295 | 2.321853 | 26.072435 | 47.009691 | 20.246629 | 3.590710 | ... | 0.532657 | 0.331571 | 0.448411 | 0.64 | 0.523415 | -0.638090 | 0.325449 | 0.515422 | 0.52 | NaN |
| ts_4 | 0.976807 | 0.953125 | 0.906738 | 0.856689 | 0.813721 | 3.314088 | 47.505651 | 36.356375 | 10.970250 | 3.584427 | ... | 9.644766 | 0.000000 | 7.529028 | 0.04 | 0.240547 | -1.173620 | 0.245583 | 0.819281 | 0.22 | NaN |
| ts_5 | 0.979492 | 0.957764 | 0.914795 | 0.870605 | 0.833008 | 2.491926 | 17.374024 | 55.482169 | 22.264773 | 2.873072 | ... | 6.303317 | 0.000000 | 4.622768 | 0.04 | 0.400100 | -0.841443 | 0.257640 | 0.789540 | 0.40 | NaN |
5 rows × 4573 columns
(4) Clean the results table¶
Not all features returned by pyhctsa will be well-behaved on every dataset. To perform downstream analyses such as classification, we must first filter out special-valued features and NaNs:
[10]:
res_clean = (
res.replace([np.inf, -np.inf], np.nan)
.dropna(axis=1)
)
[11]:
res_filtered = res_clean.dropna(axis=1)
Filter out non-numeric
[12]:
res_num = res_filtered.apply(pd.to_numeric, errors="coerce")
good_cols = res_num.notna().eq(res.notna()).all(axis=0)
res_num_strict = res_num.loc[:, good_cols]
Filter out zero variance (constant) columns
[13]:
zero_var_cols = res_num_strict.columns[res_num_strict.var(axis=0, skipna=True) == 0]
zero_var_cols
[13]:
Index(['add_noise_1_quantiles_10.pcrossmean', 'add_noise_1_even_10.pcrossmean',
'add_noise_1_std1_10.pcrossmean', 'add_noise_1_gaussian.pdec',
'add_noise_1_gaussian.pcrossmean', 'add_noise_1_kraskov1_4.pcrossmean',
'translate_shape_circle_1p5_pts.max',
'translate_shape_circle_1p5_pts.mode',
'translate_shape_circle_2p5_pts.max',
'translate_shape_circle_2p5_pts.mode',
...
'ar_fit_1_8_sbc.popt_sbc', 'ar_fit_1_8_sbc.popt_fpe',
'ar_fit_1_8_sbc.res_siglev', 'walker_prop_0p1.res_runstest',
'walker_prop_0p5.res_runstest', 'walker_prop_0p9.res_runstest',
'walker_prop_1p1.res_runstest', 'walker_biasprop_0p5_0p1.res_runstest',
'walker_biasprop_0p1_0p5.res_runstest',
'walker_momentum_5.res_runstest'],
dtype='str', length=103)
[14]:
good_features_df = res_num_strict.drop(columns=zero_var_cols)
[15]:
good_features_df
[15]:
| hrv_classic.pnn5 | hrv_classic.pnn10 | hrv_classic.pnn20 | hrv_classic.pnn30 | hrv_classic.pnn40 | hrv_classic.lfhf | hrv_classic.vlf | hrv_classic.lf | hrv_classic.hf | hrv_classic.tri | ... | surrogate_test_RP_99_o3.o3_p | surrogate_test_RP_99_o3.o3_zscore | surrogate_test_RP_99_o3.o3_f | surrogate_test_RP_99_o3.o3_mediqr | surrogate_test_RP_99_o3.o3_prank | surrogate_test_RP_99_tc3.tc3_p | surrogate_test_RP_99_tc3.tc3_zscore | surrogate_test_RP_99_tc3.tc3_f | surrogate_test_RP_99_tc3.tc3_mediqr | surrogate_test_RP_99_tc3.tc3_prank | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | |||||||||||||||||||||
| ts_1 | 0.988037 | 0.975098 | 0.943359 | 0.915039 | 0.887207 | 1.438589 | 16.373641 | 38.574764 | 26.814297 | 3.080451 | ... | 2.658684e-02 | -2.217531 | 0.000000 | 1.393878 | 0.02 | 0.004159 | 2.865863 | 0.011524 | 2.146499 | 0.06 |
| ts_2 | 0.979736 | 0.959473 | 0.916504 | 0.875244 | 0.831299 | 1.910163 | 16.994118 | 50.579037 | 26.478908 | 2.559026 | ... | 8.124138e-01 | 0.237313 | 0.345205 | 0.250219 | 0.78 | 0.010484 | -2.559445 | 0.000000 | 1.908045 | 0.02 |
| ts_3 | 0.979492 | 0.960938 | 0.929443 | 0.891602 | 0.852295 | 2.321853 | 26.072435 | 47.009691 | 20.246629 | 3.590710 | ... | 5.942707e-01 | 0.532657 | 0.331571 | 0.448411 | 0.64 | 0.523415 | -0.638090 | 0.325449 | 0.515422 | 0.52 |
| ts_4 | 0.976807 | 0.953125 | 0.906738 | 0.856689 | 0.813721 | 3.314088 | 47.505651 | 36.356375 | 10.970250 | 3.584427 | ... | 5.172918e-22 | 9.644766 | 0.000000 | 7.529028 | 0.04 | 0.240547 | -1.173620 | 0.245583 | 0.819281 | 0.22 |
| ts_5 | 0.979492 | 0.957764 | 0.914795 | 0.870605 | 0.833008 | 2.491926 | 17.374024 | 55.482169 | 22.264773 | 2.873072 | ... | 2.913416e-10 | 6.303317 | 0.000000 | 4.622768 | 0.04 | 0.400100 | -0.841443 | 0.257640 | 0.789540 | 0.40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| ts_496 | 0.984375 | 0.970215 | 0.944824 | 0.917725 | 0.889648 | 0.336630 | 13.870277 | 18.356541 | 54.530277 | 3.028086 | ... | 8.572270e-02 | -1.718405 | 0.108641 | 1.331643 | 0.10 | 0.525572 | -0.634780 | 0.314154 | 0.460967 | 0.58 |
| ts_497 | 0.989990 | 0.981934 | 0.962158 | 0.946045 | 0.925537 | 0.197599 | 2.498134 | 6.366314 | 32.218319 | 4.028515 | ... | 8.857211e-24 | -10.053599 | 0.000000 | 9.243120 | 0.02 | 0.384554 | 0.869537 | 0.297431 | 0.481377 | 0.48 |
| ts_498 | 0.987549 | 0.976074 | 0.952881 | 0.928955 | 0.905029 | 0.297679 | 8.875599 | 16.243974 | 54.568739 | 3.149116 | ... | 5.731781e-11 | -6.550570 | 0.000000 | 4.600939 | 0.02 | 0.039565 | 2.058260 | 0.065244 | 1.510814 | 0.12 |
| ts_499 | 0.990723 | 0.982178 | 0.962891 | 0.941406 | 0.926270 | 0.487491 | 6.891783 | 12.990598 | 26.647876 | 3.158828 | ... | 5.604103e-05 | -4.028889 | 0.000000 | 3.096691 | 0.02 | 0.241729 | 1.170676 | 0.277370 | 0.641031 | 0.24 |
| ts_500 | 0.990723 | 0.978516 | 0.961914 | 0.946289 | 0.928955 | 0.773377 | 5.006532 | 16.483592 | 21.313790 | 3.330894 | ... | 9.240631e-02 | -1.682839 | 0.093285 | 1.497840 | 0.16 | 0.753890 | -0.313514 | 0.369732 | 0.328641 | 0.64 |
500 rows × 4374 columns
[32]:
from pyhctsa.utils import SigmoidScaler
[33]:
ss = SigmoidScaler(do_scale=True)
[34]:
ss_fit = ss.fit(good_features_df)
[35]:
good_features_df_N = ss.transform(good_features_df)
Normalise features to standardise their respective scales
[ ]:
# good_features_df_N = MinMaxScaler().fit_transform(good_features_df)
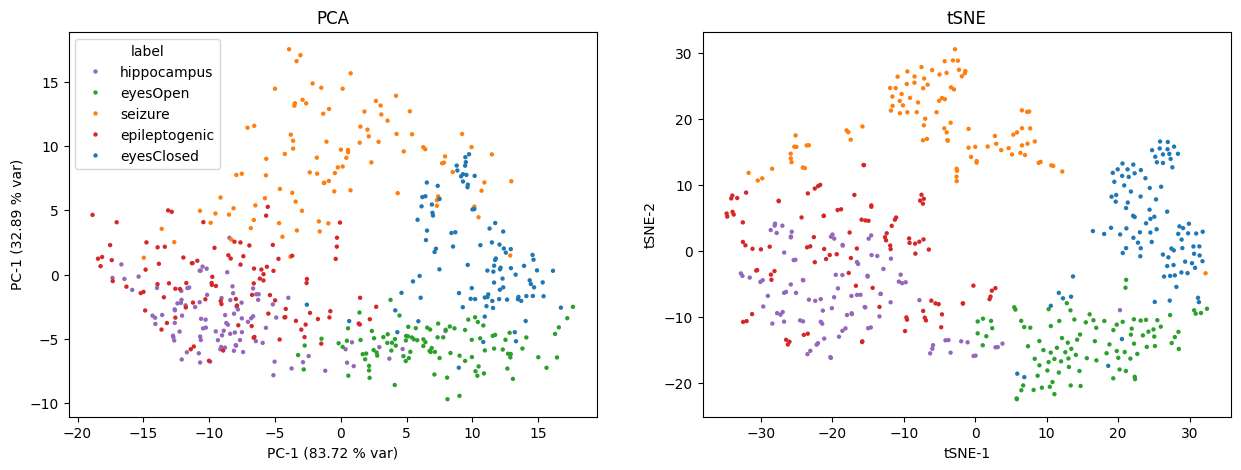
🖥 (5) Visualisation¶
To get a sense of how the pyhctsa features capture dimensions along which different types of dynamics can be distinguished, we can use linear dimensionality reduction methods such as PCA, or non-linear methods such as t-SNE to visualise how time-series instances cluster or separate:
[36]:
pc_fit = PCA(n_components=2).fit(good_features_df_N)
pc = pc_fit.transform(good_features_df_N)
pc_df = pd.DataFrame(pc, columns=['PC1', 'PC2'])
pc_df['label'] = df_series['label'].to_numpy()
[37]:
tsne_fit = TSNE(n_components=2, perplexity=30, random_state=42).fit_transform(good_features_df_N)
tsne_df = pd.DataFrame(tsne_fit, columns=['tSNE1', 'tSNE2'])
tsne_df['label'] = df_series['label'].to_numpy()
[38]:
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
palette = {
"epileptogenic": "#d62728",
"eyesClosed": "#1f77b4",
"eyesOpen": "#2ca02c",
"hippocampus": "#9467bd",
"seizure": "#ff7f0e",
}
#sns.kdeplot(data=pc_df, x='PC1', y='PC2', hue='label', alpha=0.4)
sns.scatterplot(data=pc_df, x='PC1', y='PC2', hue='label', palette=palette, ax=ax[0], s=10, linewidth=0)
ax[0].set_xlabel(f'PC-1 ({np.round(pc_fit.explained_variance_[0], 2)} % var)')
ax[0].set_ylabel(f'PC-1 ({np.round(pc_fit.explained_variance_[1], 2)} % var)')
ax[0].set_title("PCA")
sns.scatterplot(data=tsne_df, x='tSNE1', y='tSNE2', hue='label', palette=palette, ax=ax[1], s=10, linewidth=0)
ax[1].set_title('tSNE')
ax[1].set_xlabel('tSNE-1')
ax[1].set_ylabel('tSNE-2')
ax[1].legend().remove()
plt.show()
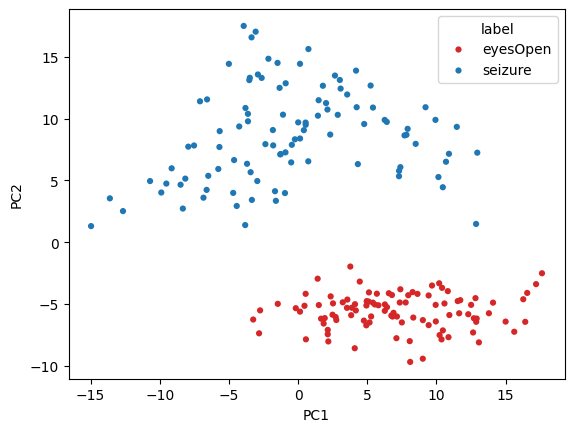
Seizure vs Eyes Open¶
[39]:
subset_df = pc_df[(pc_df['label'] == 'eyesOpen') | (pc_df['label'] == 'seizure')]
[40]:
palette2 = {
"eyesOpen": "#d62728",
"seizure": "#1f77b4",
}
sns.scatterplot(data=subset_df, x='PC1', y='PC2', hue='label', palette=palette2, s=20, linewidth=0)
plt.show()
📂 Classification Problem¶
Let’s now try to classify between the five groups using a simple linear SVM classifier. Here we will use 10-fold cross validation with a linear SVM and default parameters
[28]:
# create source dataset
df_source = good_features_df
df_source['label'] = df_series['label'].to_numpy()
X = df_source.drop(columns=['label']).to_numpy()
y = df_source['label'].to_numpy() # classes
[29]:
skf = StratifiedKFold(n_splits=10, random_state=0, shuffle=True)
[31]:
per_fold_accuracy = {}
for i, (train_index, test_index) in enumerate(skf.split(X, y)):
print(f"Fold {i}:")
# construct training set and test set
X_train, y_train = X[train_index, :], y[train_index]
X_test, y_test = X[test_index, :], y[test_index]
# fit the scaler to the training set
ss = SigmoidScaler(do_scale=False).fit(X_train)
X_train_N = ss.transform(X_train)
X_test_N = ss.transform(X_test)
# fit the linear SVM
sv = LinearSVC(max_iter=10_000).fit(X_train_N, y_train)
# because classes are balance, acc is automatically the bal acc
score = sv.score(X_test_N, y_test)
print(f'Classifcation accuracy: {score}')
per_fold_accuracy[f'fold {i+1}'] = score
# print overall mean accuracy across the 10 folds
mean_fold_acc = np.mean([per_fold_accuracy[v] for v in per_fold_accuracy])
print(f'Mean (across folds) accuracy (5-class) using 10-fold svm_linear classification: {mean_fold_acc*100}%')
Fold 0:
Classifcation accuracy: 0.88
Fold 1:
Classifcation accuracy: 0.92
Fold 2:
Classifcation accuracy: 0.96
Fold 3:
Classifcation accuracy: 0.94
Fold 4:
Classifcation accuracy: 0.98
Fold 5:
Classifcation accuracy: 0.88
Fold 6:
Classifcation accuracy: 0.96
Fold 7:
Classifcation accuracy: 0.96
Fold 8:
Classifcation accuracy: 0.88
Fold 9:
Classifcation accuracy: 0.94
Mean (across folds) accuracy (5-class) using 10-fold svm_linear classification: 93.0%
[ ]: